Actual cost of IT downtime: A Guide

Today, we will cover the allied costs that come along with downtime:
- Revenue loss
- Penalties
- Rebuilding reputation
- Wages
- Ransom
Starting with the obvious: Revenue loss
Let's say your organization's business is comparable to a leading e-commerce operator's. Taking the numbers from their official reports (link to the quarterly revenue report), every minute of a downtime will cost them $1.21 million. Most public clouds promise 99.999% availability. Based on these numbers, the aforementioned business could still lose $636.46 million annually.
These are only guidelines, but the potential revenue loss during an outage is still staggering. Revenue generated and revenue loss during downtime are directly proportional.
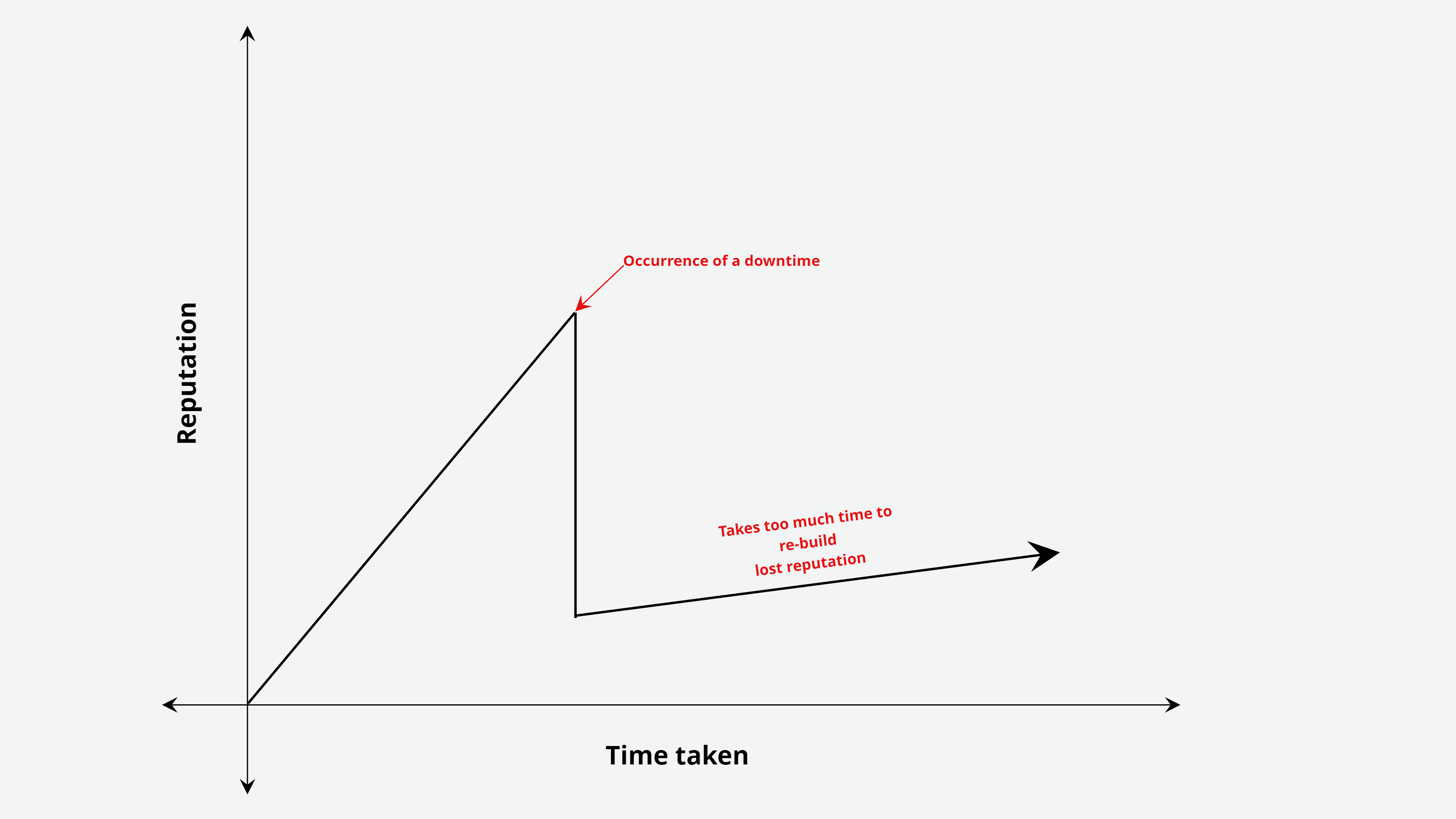
Reputation loss: The long road ahead
While reputation rebuilding activities usually include marketing campaigns, PR exercises, and statements, it takes longer to rebuild a damaged reputation. Did you know that an independent security researcher was offered $10,000 just to not publish an article on a cyberattack? This questionable act is an attempt to protect their reputation. A ruined reputation directly impacts customer retention, new business acquisition, and stock price.
Penalties: To regulatory bodies and customers
Many governmental and regulatory bodies enforce strict benchmarks for uptime. Any shortfall in meeting these standards will result in penalties. In addition to regulatory bodies, most B2B contracts enforce an availability SLA. Failure to keep up with the availability SLA will result in paying penalties to the customer as well. For example, the DORA regulations levy a fine of either 2% of an organization's worldwide annual turnover or 1% of global daily turnover. The cost incurred for the legal expenses should also be considered.
Ransoms: Unplanned factors to consider
In the unfortunate event of ransomware attacks, even if the ransom has been paid by insurance, the increase in premium is still a factor to consider. In most of the cases, the ransom will be paid by insurance and from the organization's treasury.
Wage: Internal and external
Downtime usually results in your employees working around the clock searching for the cause, fixing the problem, and restoring operations. In this process, you may even require the help of third-party businesses like consultants and insurance companies. The downtime's negative effect on morale and extended work hours also indirectly causes a loss of productivity in your teams, which translates into increased cost to the organization to continue business as usual.
Downtime = Bad for business
Now that we have established the actual cost of downtime, let us see the measures to take for preventing a downtime.
Most of the outages start small. It could be anything minor like:
- One misconfigured container
- One offline server
- One killed service
- One full disk partition
- One offline port
- One file deleted, and so many more seeming harmless anomalies.
Improving your defense against downtime
The goal should be to eliminate downtime and, when it occurs, to detect it as early as possible. Most downtime costs more because the organization was not able to find the cause in time.
With observability, you can proactively avoid downtime and also fix it by finding the root cause in seconds. With the tech-stack evolving and providing more and more powerful features, it also gets complex.
You need an enterprise grade observability tool to monitor every layer of your IT infrastructure. This helps in pin-pointing the cause of the problem and keep your mean time to repair (MTTR) down. You need monitoring at every level to know the origin of a potential downtime or an outage that has already occurred. Let's learn more.
The cause of downtime is mostly hidden
Keeping an eye on one server, one container, or one database is easy. But organizations cannot function with that. Every single performance metric and availability status is important to protect your entire IT infrastructure. In your IT infrastructure containing 1,000s of servers, 100s of databases, and millions of pods and containers, pin-pointing one defective component that could lead to an outage is a herculean task.

Even then, many organizations fall into the tool-sprawl trap where they first incorporate multiple tools to monitor individual facets of their IT infrastructure, then look for a tool because those multiple tools are in different places and they don't talk to each other. So they bring another tool to have a single source of truth, which in turn adds to the tool-sprawl and a huge bill to pay.
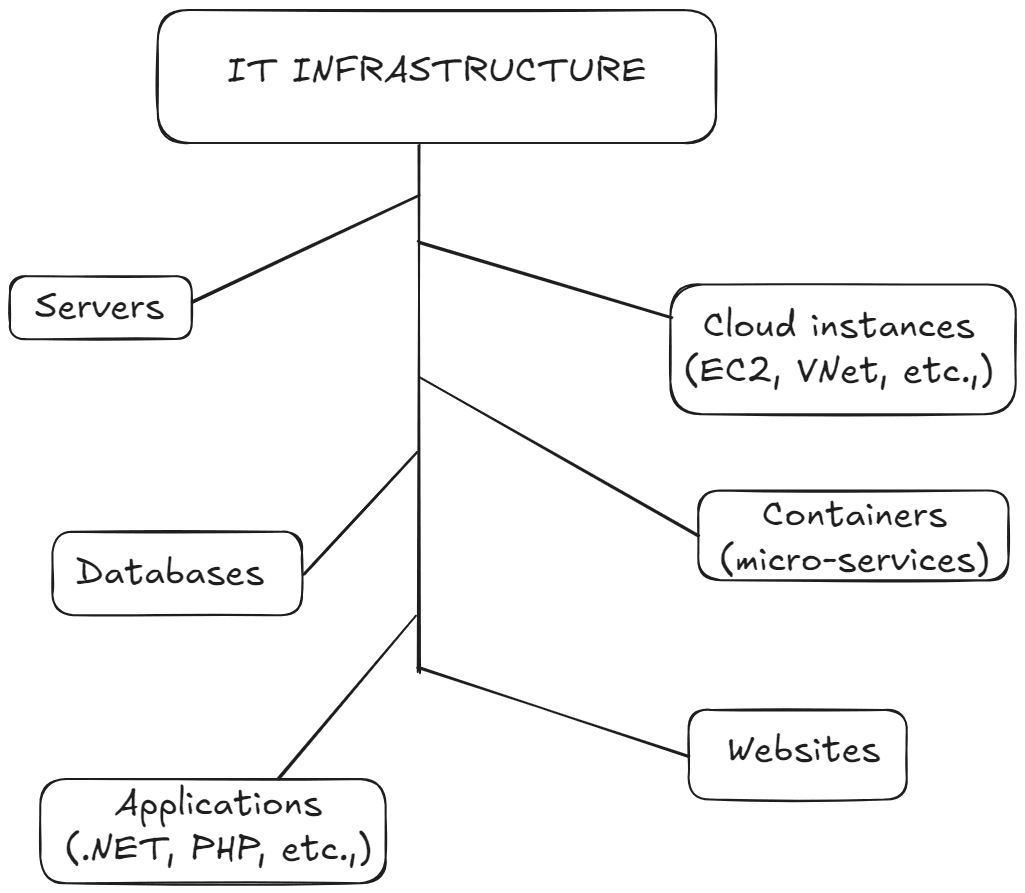
Need for a single pane of glass
Site24x7 is the only solution you need to encompass your entire IT infrastructure under an enterprise grade observability platform. Our server monitoring platform is vendor-agnostic. It can run on on-premises, clouds, VMs, Windows, Linux, macOS, FreeBSD, or any other Linux distribution based servers, with an additional arsenal of auto-remediation capabilities to fix your downtime problems at the first sight of trouble.
Be it servers, cloud resources, containers, applications, network devices, or websites, Site24x7 is the one browser tab you have to keep open. In short, you get complete observability against downtime with the benefit of zero tool-sprawl. But why should you choose Site24x7?
In simpler words from Gartner,
Utilize our AI powered observability platform and cut-down downtime costs like thousands of our enterprise customers. With our lightweight yet robust enterprise-grade server monitoring agent, you have easy access to every single patch available for your server's configuration. Information is not just limited to the updates available—you also get key metrics like availability and performance of the CPU, memory, disk, services, processes, and much more. Try Site24x7's server monitoring suite now.
Topic Participants
Geoffrin Edwin